LLMs Unkept Promise


The AI Promise That Never Delivers
Apple Intelligence has been out for about a year now, but like most AI promises, it has fallen short of expectations.
The AI hype machine has been driven by the alluring promise of AGI (Artificial General Intelligence). Countless movies and novels explore worlds where such AGIs exist—from HAL 9000 to Skynet to Samantha from Her.
But despite half a decade of promises, Apple Intelligence is just the latest example of these products missing the mark.
Apple Intelligence was announced at WWDC in June 2024, but didn't ship with the brand new iPhones and other hardware announced then. Months later, we got some very mediocre features. Eventually, we received "liquid glass" effects and text message summaries.
"The really good stuff is coming," we're promised.
I believe we've heard that before.
What Actually Works link
Let's tighten up our definitions and see what AI actually excels at.
AI (or ML—machine learning for those in the field) is a wide discipline containing many fields that are so well-integrated into our tools that we forget about them.
A few examples: searching for something using a photo instead of text description is AI. Voice recognition is AI. Generative fill for editing out unwanted parts of images is also AI. These features are all AI tools.
format_quote"Do you know what they call alternative medicine that's been proved to work? Medicine." — Tim Minchin
When AI technology works, we stop calling it AI. It fades into the background of our normal workflow.
This article is really about generative AI, large language models, and GPT. Huge companies have been making huge promises but delivering very little.
The Language vs. Knowledge Problem link
LLMs like ChatGPT are great at comprehending language. They're excellent as a thesaurus or as an alternative to a search engine. But start using them for knowledge rather than language, and you see where the problem begins.
With LLMs, the more specific the answers you want, the less reliable large language models become.
Here's a practical demonstration: pick a book you have and ask whatever GPT you're using to give a brief summary. It will give something accurate. Now ask about the chapters (for fictional books, this isn't so relevant, but for science or engineering textbooks, you'll see where this goes). You'll start to notice the answers get more made up. Go further and ask about the contents of the chapters and which you should pay attention to.
It will confidently give you a made-up answer. It has approximate knowledge, but that's really it.
GPT's Strengths vs. Weaknesses link
To visualize this concept, below is a summary of what LLMs (like GPT) are good at and where they struggle.
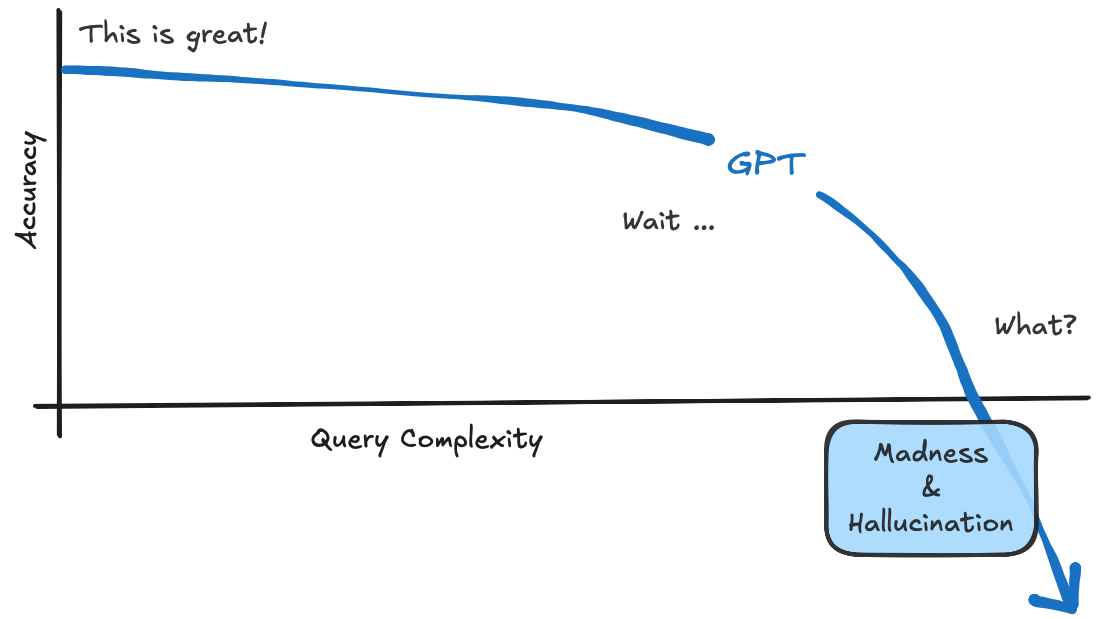
I've found this to be true across many different models, whether it's OpenAI, Claude, or whatever else is out there.
For an SDET, this is actually fine. There's tremendous value on the left side of the graph for initial research, debugging, and essentially Googling when you forget Playwright syntax.
But there are real limits that encroach on you very quickly as you try to use them for complex work. Let's explore why this happens.
Where Are the Limits? link
GPT is essentially autocorrect trained on the entire internet with enough complexity to pass the Turing test. It almost always offers sensible suggestions about what should come next in a sentence. However, language ability is not intelligence. We often confuse great language skills for intelligence, which is where the technology gets misused.
You aren't chatting with an intelligent agent—it's autocompleting your questions, much like a sociopath getting under your skin by saying what it thinks you want to hear.
This isn't just my opinion. Apple researchers published a study called "The Illusion of Thinking" that found LLMs may appear to perform logical reasoning, but they often rely on pattern recognition rather than genuine understanding. The researchers observed that even slight changes in question wording could lead to significantly different answers, highlighting the fragility of these models' reasoning capabilities.
Large language models can only be trained on topics where there's a large amount of language available. The developers working on StarCraft 2 had recordings of competitive matches from the best players, which they used to train their AI AlphaStar. AlphaStar was trained on the equivalent of 200 years of pro-level gameplay.
Notice that LLMs can't autocomplete math outside of trivial examples—the state space of all numbers is too great to expect much existing training data. Something trivial like 1 + 1 = 2 is written ad nauseam in textbooks, which is easy for any GPT to complete. But ask it to solve 2e² + 5x = 0, and it struggles because there isn't enough training data for complex mathematical expressions.
GPTs are excellent when you initially query something, but when you dig deeper, they start to fall apart and get increasingly inaccurate or just provide surface-level responses.
It's not that this tech is new and will eventually get better. This tech only works after being trained on large amounts of data.
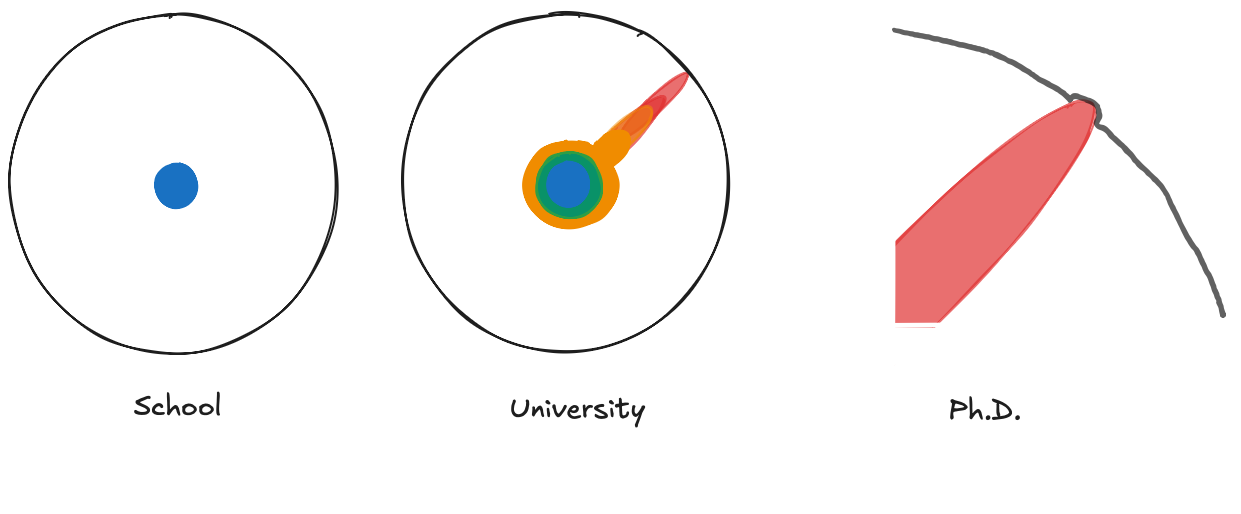
On very niche topics which may have only a handful of PhD or research papers written on them, GPT will never learn that information because a handful of PhD papers isn't a large amount of language. If you don't have a large amount of language, you can't train a large language model.
In this sense, AI companies can't fulfill their wild promises—so why make them?
The Real Audience: Investors, Not Users link
The disconnect between hype and reality becomes clearer when you realize who these promises are actually for.
The hype rhetoric and reality are very different, but we aren't the audience for all this hype. Taking these claims at face value, these technologies just don't work. And you can't sell a product that doesn't work.
So why make these promises?
It's not the end user, not the engineers, or even the C-suite execs. It's the wealthy investors who demand that LLMs be crammed into everything we use, whether it makes sense or not, as companies need to impress their investors with AI features—even if they don't work well.
The logic behind this is that rather than selling products and services to users for money (which is the traditional way of getting cash flow), it's now easier to persuade investors to part with more of their capital by selling a promise. Selling products and services is hard work, while selling these promises is easy. It's always easier to promise a bright future than build a better present.
What This Means for Us link
None of us want things that only appear to work. It's important to pay less (or no) attention to what companies say their tech will do in the future, and far more to what they actually do today.
The Benchmark Illusion link
But wait—what about all these impressive benchmarks showing superhuman performance?
The superhuman performance in some areas does make you pause. The hype again is that AI will start replacing humans in many high-skill industries.
AGI, as pointed out above, is a lie.
And the problem for AI is that it isn't even headed in the right direction. Bold claim when what we have for AI now can outperform humans on such a wide variety of tasks?
How we measure progress with benchmarks, and how those benchmarks influence the direction of research. Not a single popular benchmark for LLMs actually measures intelligence.
This aligns with what Apple researchers found in their study—even when LLMs appear to perform well on benchmarks, their reasoning is often fragile and dependent on pattern matching rather than true understanding.
Intelligence is not a measure of how many tasks you can do. This is the definition of intelligence:
format_quote"The ability to acquire and apply knowledge and skills."
Every benchmark out there currently tests the ability of a model to apply knowledge, but none of them focus on the agent's ability to acquire knowledge. The most cutting-edge models almost entirely lack the ability to continually learn.
You can train them once on large amounts of language, but after that, their ability to acquire new knowledge is extremely limited. And that's a big problem! There is some in-context learning per chat (which uses up tokens).
What Real AGI Would Look Like link
So if current AI isn't headed toward true intelligence, what would a real AGI actually need?
For an AGI, collecting enough data or making the agent big enough to know everything on the internet and beyond is just not possible. There's an infinite amount of knowledge out there—no agent can know it all, and it isn't necessary.
I would like to have an agent that can learn from anything. An agent that has goals and can autonomously control its data stream and teach itself based on such goals.
This is a hard problem, but a very compelling one! If an AI agent needs millions of examples to learn something, then it can't really learn anything. It can only learn things for which millions of examples exist.
I want an agent to learn much like a human, via back-and-forth interactions, rather than from millions of pre-generated examples. More importantly, I would like this agent to use that knowledge to go off and continually learn on its own. It should be learning autonomously even without direct human intervention.
It would be nice with the prompt interface to have an AI agent learn your preferences without it being a whole Black Mirror episode of digital cloning.
At the moment, the prominent promise of AGI is this idea of the single all-knowing agent that has seen so much data that it can generalize to anything. This completely fails to include the importance of learning, and this notion is just absurd.
Before the current state of machine learning, there was reinforcement learning. In the past, AI learning was about differentiating photos of animals from other objects via continual learning. Intelligence is fundamentally about the ability to learn.
Now, the LLM does all the learning during the training phase, goes through some testing, gets deployed, and that's it. This needs to be combined into a single phase where the agent is learning and doing.
There are problems of loss of plasticity and catastrophic forgetting. But there are efforts to avoid this.
In-context learning has frozen parameters and limits on learning, which is stored temporarily until that information exits the context window.
Single, Experiential Stream of Data link
This is the opposite of how LLMs are trained. A model doesn't know how to act over longer time horizons because it's trained on lots of disjointed training data. However, at some point, it will need to learn on new data that appears over time. This is where an agent interacting with the world would generate experiences it can learn from.
Scaling with Compute link
We need these AIs to perform better when there's more compute. This fails at present because AI agents can't learn without massive internet datasets. Current LLMs only scale on both compute and data, which is incredibly inefficient.
The Bottom Line link
The AI revolution we were promised isn't coming from the current crop of LLMs. They're sophisticated language models, not intelligent agents. They excel at tasks that require pattern matching across vast amounts of text, but fail when asked to truly understand, learn, or reason.
For SDETs and developers, this means using AI tools for what they're good at—initial research, syntax help, and brainstorming—while being realistic about their limitations. The real breakthrough will come when we figure out how to build systems that can actually learn and adapt, not just regurgitate patterns from training data.
Until then, the "AI revolution" remains a promise that keeps getting pushed further into the future.
Feel free to update this blog post on GitHub, thanks in advance!
Share this post
Support me
I appreciate it if you would support me if you have enjoyed this post and found it useful, thank you in advance.